
1.likely
likely在redis中有涉及到。对于写python的比较陌生,其中jemlloc模块用了很多次,但这个还没分析过,后续分析。于是在网上找到相关分析文章进行总结:
http://velep.com/archives/795.html
https://developer.aliyun.com/article/383873
#ifndef likely
#define likely(x) __builtin_expect(!!(x), 1)//表示x的值为真的可能性更大
#endif /* likely */
#ifndef unlikely
#define unlikely(x) __builtin_expect(!!(x), 0) //表示x的值为假的可能性更大
#endif /* unlikely */
__builtin_expect()是GCC提供给程序员使用的,目的是将”分支转移”的信息提供给编译器,这样编译器可以对代码进行优化,以减少指令跳转带来的性能下降。 __builtin_expect(!!(x), 1)表示x的值为1的可能性更大 __builtin_expect(!!(x), 0)表示x的值为0的可能性更大
查看GCC文档:
-- Built-in Function: long __builtin_expect (long EXP, long C)
You may use `__builtin_expect' to provide the compiler with branch
prediction information. In general, you should prefer to use
actual profile feedback for this (`-fprofile-arcs'), as
programmers are notoriously bad at predicting how their programs
actually perform. However, there are applications in which this
data is hard to collect.
The return value is the value of EXP, which should be an integral
expression. The value of C must be a compile-time constant. The
semantics of the built-in are that it is expected that EXP == C.
For example:
if (__builtin_expect (x, 0))
foo ();
would indicate that we do not expect to call `foo', since we
expect `x' to be zero. Since you are limited to integral
expressions for EXP, you should use constructions such as
if (__builtin_expect (ptr != NULL, 1))
error ();
when testing pointer or floating-point values.
if (__builtin_expect (x, 0)) foo (); 表示期望x == 0,也就是期望不执行foo()函数;同理,if (__builtin_expect (ptr != NULL, 1)) error (); 表示期望指针prt非空,也就是期望看到error()函数的执行。
通过这种方式,编译器在编译过程中,会将可能性更大的代码紧跟着后面的代码,从而减少指令跳转带来的性能上的下降。比如 :
if (likely(a>b)) {
fun1();
}
if (unlikely(a<b)) {
fun2();
}
这里就是程序员可以确定 a>b 在程序执行流程中出现的可能相比较大,因此运用了likely()告诉编译器将fun1()函数的二进制代码紧跟在前面程序的后面,cache在预取数据时就可以将fun1()函数的二进制代码拿到cache中。这样,也就添加了cache的命中率。同样的,unlikely()的作用就是告诉编译器,a<b 的可能性很小所以这里在编译时,将fun2()的二进制代码尽量不要和前边的编译在一块。
咱们不用对likely和unlikely感到迷惑,须要知晓的就是 if(likely(a>b)) 和 if(a>b)在功能上是等价的,同样 if(unlikely(a<b)) 和 if(a<b) 的功能也是一样的。
新疑惑:一般条件判断的概率都不是五五开,那什么时候使用likely关键字更划得来呢。
2.符号速度
在前面对dictfind的函数进行优化的时候:issue:https://github.com/redis/redis/pull/9838/files
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h;
long idx_0, idx_1;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
idx_0 = h & DICTHT_SIZE_MASK(d->ht_size_exp[0]);
if (likely(d->rehashidx < idx_0)){
he = d->ht_table[0][idx_0];
} else {
idx_1 = h & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
he = d->ht_table[1][idx_1];
}
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
return NULL;
}
其中的idx_0和idx_1其实是有一定的关系的,因为table1的大小总是table0的两倍,而哈希值是固定的,而且DICTHT_SIZE_MASK其实就是2的n次方-1,换为二进制就是N个1
#define DICTHT_SIZE(exp) ((exp) == -1 ? 0 : (unsigned long)1<<(exp))
#define DICTHT_SIZE_MASK(exp) ((exp) == -1 ? 0 : (DICTHT_SIZE(exp))-1)
idx_0 = h & DICTHT_SIZE_MASK(d->ht_size_exp[0]);
idx_1 = h & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
比如hash值的二进制为:1000111
DICTHT_SIZE_MASK(d->ht_size_exp[0])为:111
DICTHT_SIZE_MASK(d->ht_size_exp[1])则为:1111(比上面多一个1)
所以hash & DICTHT_SIZE_MASK(d->ht_size_exp[0])的结果就是:111和111,但如果hash值的第四位也是1,那么结果就变为了:111和1111,所以idx0和idx1就有如下关系:
已知idx_0和hash的二进制:
idx_1 = idx_0 + hash & 1 << exp
而原来的idx_1的获取方式为:
idx_1 = hash & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
但从代码层面分析,我改进后的方法除了需要&还需要«和+的运算,其实原来的方法在取DICTHT_SIZE_MASK的值的时候时需要两个判断和一次减法和一次位移的,但对于idx_1来讲其实exp已经不会是-1了,那两次判断其实是多余的。
然后再讨论以下C语言中位移、加减乘除、& 、%等符号的运算速度。
https://blog.csdn.net/morgerton/article/details/64918560
3.C语言的整数类型
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx_0, idx_1;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
idx_0 = h & DICTHT_SIZE_MASK(d->ht_size_exp[0]);
if (d->rehashidx < idx_0){
he = d->ht_table[0][idx_0];
} else {
idx_1 = h & DICTHT_SIZE_MASK(d->ht_size_exp[1]);
he = d->ht_table[1][idx_1];
}
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
return NULL;
}
之前redis的修改重新编译后,虽然编译过程中有告警,但是还是编出来了,但是当redis-cli去连接redis-server的时候redis-server就报错了
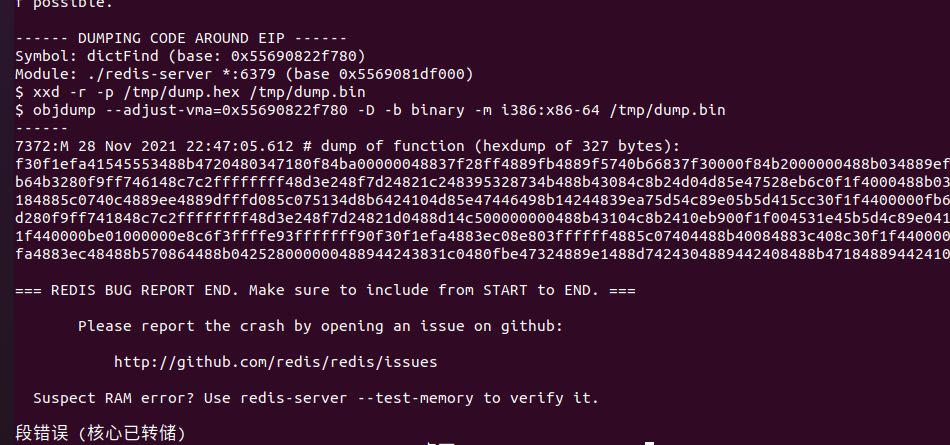
于是就gdb进去看下问题
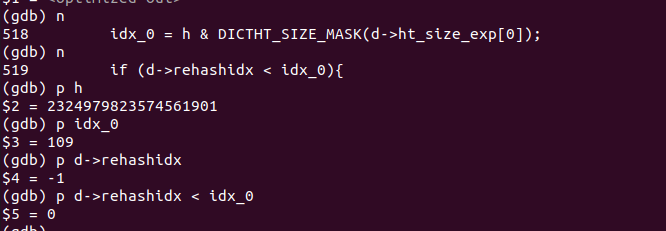
可以看到d->rehashidx为-1,idx_0为109,但是在进行判断的时候d->rehashidx < idx_0的结果为false。接下来打出来两者的类型:
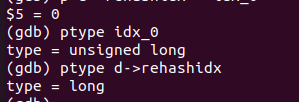
可以看出我们的新变量idx_0设置的uint_64t但是显示出来的就是unsigned long
/* Unsigned. */
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
#ifndef __uint32_t_defined
typedef unsigned int uint32_t;
# define __uint32_t_defined
#endif
#if __WORDSIZE == 64
typedef unsigned long int uint64_t;
#else
__extension__
typedef unsigned long long int uint64_t;
#endif
而rehashidx确实设置的就设置为long了
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<exp) */
};
于是为何-1比109要大的原因就找到了,对于一个singed类型的long,当是-1的时候就会以补码储存
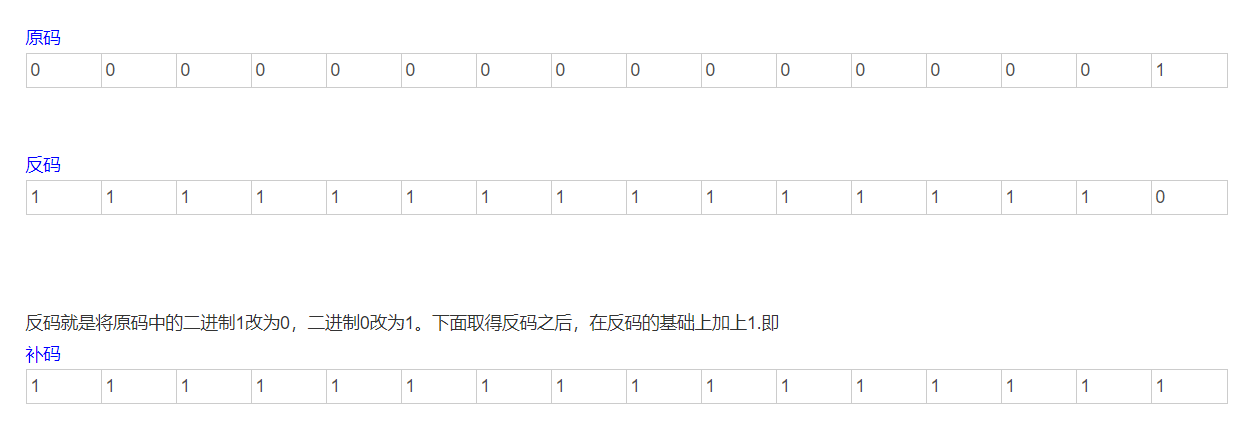
而当sign和unsign进行比较的时候,sign将转换为无符号的数字进行比较。
于是将代码中idx_0的类型改为long int就可以了。