
回忆下redis的查询,大概就是判断下是否是空、是否在rehash,然后计算出哈希值,到两个哈希表中都找找。
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
注意到里面有一个_dictRehashStep的方法是对rehash的一层封装,rehash过程之前在dict中有分析过,现在看下这个方法是如何封装的
/* This function performs just a step of rehashing, and only if hashing has
* not been paused for our hash table. When we have iterators in the
* middle of a rehashing we can't mess with the two hash tables otherwise
* some element can be missed or duplicated.
*
* This function is called by common lookup or update operations in the
* dictionary so that the hash table automatically migrates from H1 to H2
* while it is actively used. */
翻译:这个函数是rehashing中的一步,当pauserehash为0的时候执行。当我们有迭代器正在rehashing的时候不能搞混两个哈希表,否则有些元素会丢失或者重复。
static void _dictRehashStep(dict *d) {
if (d->pauserehash == 0) dictRehash(d,1);
}
这里就是判断了一下dict的pauserehash值是否为0,为0则说明不会暂停hash,这个dict的数据结构中的pauserehash之前也没有注意过,回忆下dict的数据结构
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
对于pauserehash这个值,注释只说了大于0的时候rehashing被暂停,小于0的时候说明代码错误。于是来看下源码中的合入记录:
https://github.com/redis/redis/pull/8515
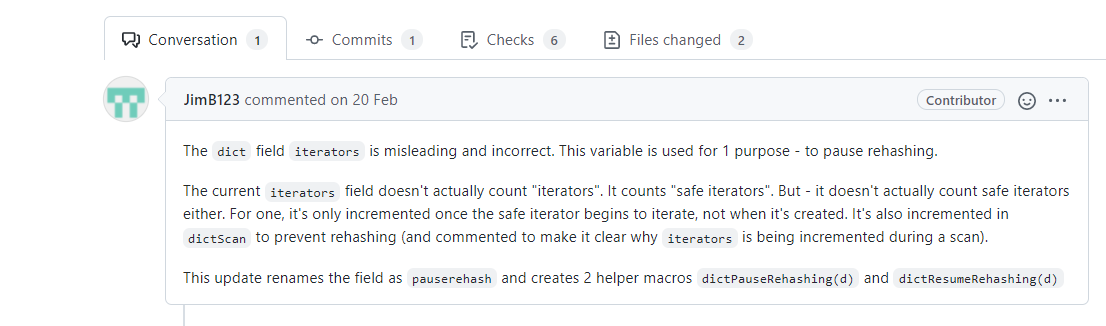

大致意思是之前dict的数据结构中有一个unsigned long iterators来记录现在正在运行的迭代器,虽然注释和变量的命名都是直接说的iterator,但其实只有安全迭代器才能会被记录。而修改者考虑到这种命名有误导的倾向,它的目的也是判断什么时候可以rehash什么时候不行于是就把整个变量改为意思更明确的pauserehash,并创立了两个宏dictPauseRehashing(d)与dictResumeRehashing(d)对其进行+1或者-1,当不为0(其实是>0)的时候就说明有安全迭代器在运行,<0的情况不应该出现。
#define dictPauseRehashing(d) (d)->pauserehash++
#define dictResumeRehashing(d) (d)->pauserehash--
而这两个宏在什么时候会用到?
dictPauseRehashing(d)
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
if (iter->entry == NULL) {
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
dictPauseRehashing(iter->d); //当迭代器还没开始迭代的时候,并且是安全迭代器就++,设置pause
else...
dictResumeRehashing(d)
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
if (iter->safe)
dictResumeRehashing(iter->d); //安全迭代器释放的时候,就--
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
两个宏还在dictscan的时候会用到,scan的其他文章分析。
明白这些后,还有个困惑。1.什么是安全迭代器;继续看到迭代器的数据结构:
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
如果safe参数被设置为1,这就是安全迭代器,意味着你能用add、find、或者其他针对dict的函数即使dict有迭代器在运行。否则那就是一个不安全的迭代器,只能调用dictNext()方法当在迭代的时候。
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
unsigned long long fingerprint;
} dictIterator;
到这里还是不太懂,继续看合入记录。
Introduced a safe iterator interface that can be used to iterate while accessing the dictionary at the same time. Now the default interface is consireded unsafe and should be used only with dictNext()
翻译:
引入了一个安全的迭代器接口,可以在同时访问字典的同时进行迭代。现在,默认接口被认为是不安全的,应仅与dictNext()一起使用
再看同步修改的内容(之前合入,非最新代码):


这里其实是吧dict的迭代器记录的内容限制为只有safe迭代器了,不safe的就不关dict的事情,就不记录了。于是要弄懂dict为啥要记录迭代器的情况。
因为redis选择了渐进式rehash,所以在一些方法里面会加入rehash的逻辑,但是如果一个dict现在保留有一个迭代器,你rehash过后,比如把我迭代器中的已经迭代过的内容放到了我未迭代后的位置,那我就有可能重复迭代,造成数据重复读,有些使用迭代器的函数不能接受这种情况,所以就要求一个安全迭代器防止rehash。
我们可以看下_dictRehashStep(判断是否能rehash)这个方法使用到的地方:
dictEntry *dictAddRaw
static dictEntry *dictGenericDelete
dictEntry *dictFind
dictEntry *dictGetRandomKey
unsigned int dictGetSomeKeys
所有要rehash的地方都需要判断迭代器的情况,确认没有安全迭代器存在才会进行rehash
找下什么地方用了安全迭代器:
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
i->safe = 1;
return i;
}
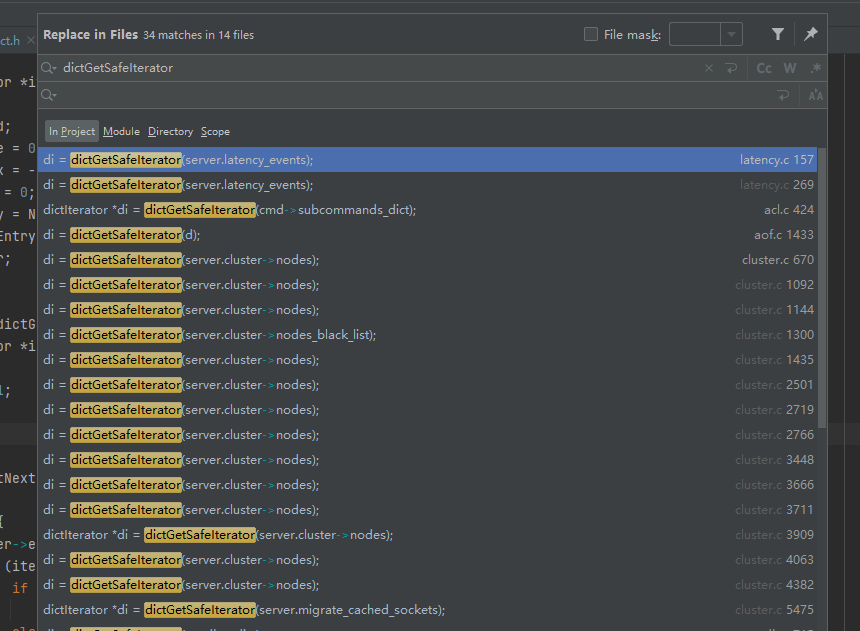
举例:rdb.c中, 就使用了安全迭代器
int rdbSaveRio(rio *rdb, int *error, int rdbflags, rdbSaveInfo *rsi) {
...
for (j = 0; j < server.dbnum; j++) {
redisDb *db = server.db+j;
dict *d = db->dict;
if (dictSize(d) == 0) continue;
di = dictGetSafeIterator(d);
使用普通迭代器的地方:
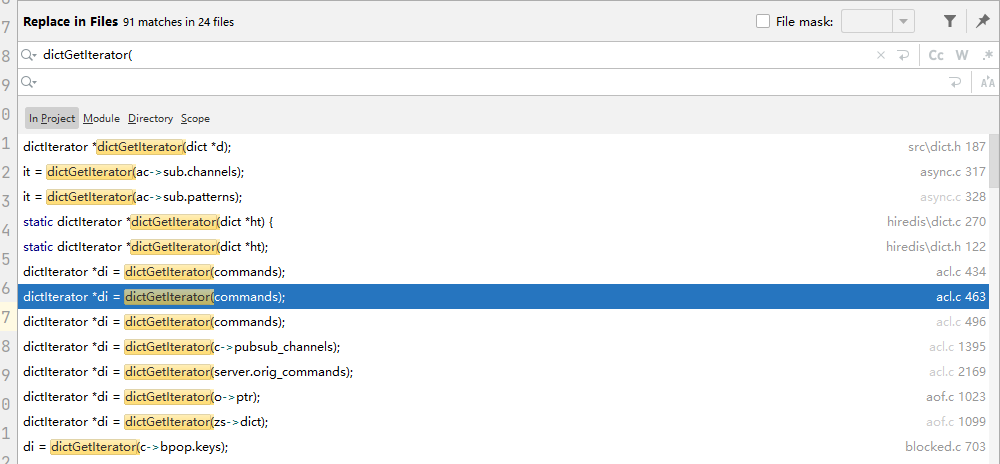
举例:aof.c中的rewriteSetObject就使用了普通迭代器
int rewriteSetObject(rio *r, robj *key, robj *o) {
...
else if (o->encoding == OBJ_ENCODING_HT) {
dictIterator *di = dictGetIterator(o->ptr);
dictEntry *de;
while((de = dictNext(di)) != NULL) {
sds ele = dictGetKey(de);
if (count == 0) {
int cmd_items = (items > AOF_REWRITE_ITEMS_PER_CMD) ?
AOF_REWRITE_ITEMS_PER_CMD : items;
if (!rioWriteBulkCount(r,'*',2+cmd_items) ||
!rioWriteBulkString(r,"SADD",4) ||
!rioWriteBulkObject(r,key))
简单一点说,那就是如果遍历过程中不允许出现重复,那就使用SafeIterator,比如下面的两种情况
- bgaofrewrite需要遍历所有对象转换称操作指令进行持久化,绝对不允许出现重复
- bgsave也需要遍历所有对象来持久化,同样不允许出现重复
至于上面设计的rdb和aof两种不同的用法,之后的文章中会进行分析。
还有dict中的指纹我们也看下是怎么来的:
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
unsigned long long fingerprint;
} dictIterator;
在dictNext中如果不是安全的迭代器,初始的时候会给指纹赋值
/* A fingerprint is a 64 bit number that represents the state of the dictionary
* at a given time, it's just a few dict properties xored together.
* When an unsafe iterator is initialized, we get the dict fingerprint, and check
* the fingerprint again when the iterator is released.
* If the two fingerprints are different it means that the user of the iterator
* performed forbidden operations against the dictionary while iterating. */
翻译:
指纹是一个64位的数组,代表整个时候的字典状态,它就是几个dict状态异或的结果。当不安全迭代器初始化的时候,我们会得到字典的指纹,当迭代器释放的时候检查指纹。如果两个指纹不一样则说明迭代器的使用者使用了违规操作在迭代的时候。
unsigned long long dictFingerprint(dict *d) {
unsigned long long integers[6], hash = 0;
int j;
integers[0] = (long) d->ht_table[0];
integers[1] = d->ht_size_exp[0];
integers[2] = d->ht_used[0];
integers[3] = (long) d->ht_table[1];
integers[4] = d->ht_size_exp[1];
integers[5] = d->ht_used[1];
/* We hash N integers by summing every successive integer with the integer
* hashing of the previous sum. Basically:
*
* Result = hash(hash(hash(int1)+int2)+int3) ...
*
* This way the same set of integers in a different order will (likely) hash
* to a different number. */
for (j = 0; j < 6; j++) {
hash += integers[j];
/* For the hashing step we use Tomas Wang's 64 bit integer hash. */
hash = (~hash) + (hash << 21); // hash = (hash << 21) - hash - 1;
hash = hash ^ (hash >> 24);
hash = (hash + (hash << 3)) + (hash << 8); // hash * 265
hash = hash ^ (hash >> 14);
hash = (hash + (hash << 2)) + (hash << 4); // hash * 21
hash = hash ^ (hash >> 28);
hash = hash + (hash << 31);
}
return hash;
}
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
if (iter->safe)
dictResumeRehashing(iter->d);
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}