
简介:
redis中是采用adlist和ziplist来实现quicklist的,adlist当控器作用,ziplist真正存着数据。
内存示意图
回忆一下adlist和ziplist的数据结构
adlist:

ziplist:

而quicklist的内存示意图:
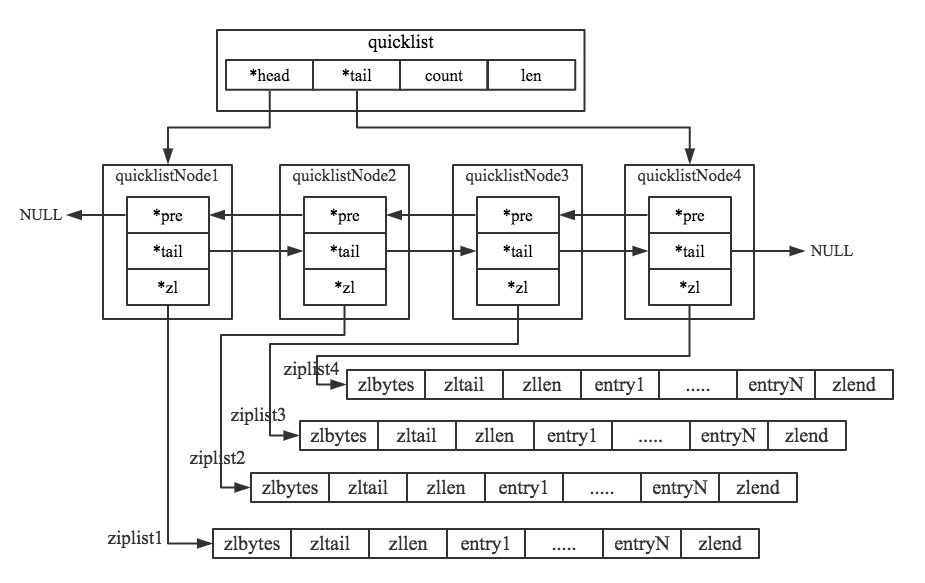
数据结构:
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: 0 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmakrs are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* ziplist大小限定,由list-max-ziplist-size给定 */
unsigned int compress : QL_COMP_BITS; /* 节点压缩深度设置,由list-compress-depth给定 */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporary decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
typedef struct quicklistIter {
const quicklist *quicklist;
quicklistNode *current;
unsigned char *zi;
long offset; /* offset in current ziplist */
int direction;
} quicklistIter;
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
unsigned char *zi;
unsigned char *value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;
设计好处:
直接对比ziplist和adlist的优劣势,ziplist更加省内存,连续内存查询速度也更快。而adlist使用指针增删改的时候对内存的动作更小,也不需要连续内存。所以quicklist综合了两个的优点,但如何设定ziplist的大小就需要根据具体的场景进行选择
如果ziplist的元素个数太少了,极端情况就是一个entry那么就和adlist没有啥区别。
如果ziplist的元素太多了,极端情况就是所有entry都放到一个ziplist中,那又和ziplist没有区别了。
Redis的配置文件中,给出了每个ziplist中的元素个数设定,考虑使用场景需求,我们可以选择不同的元素个数。该参数设置格式如下:
# Lists are also encoded in a special way to save a lot of space.
# The number of entries allowed per internal list node can be specified
# as a fixed maximum size or a maximum number of elements.
# For a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 Kb <-- not recommended for normal workloads
# -4: max size: 32 Kb <-- not recommended
# -3: max size: 16 Kb <-- probably not recommended
# -2: max size: 8 Kb <-- good
# -1: max size: 4 Kb <-- good
# Positive numbers mean store up to _exactly_ that number of elements
# per list node.
# The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size),
# but if your use case is unique, adjust the settings as necessary.
list-max-ziplist-size -2
后面的数字可正可负,正、负代表不同函数,其中,如果参数为正,表示按照数据项个数来限定每个节点中的元素个数,比如3代表每个节点中存放的元素个数不能超过3;反之,如果参数为负,表示按照字节数来限定每个节点中的元素个数,它只能取-1~-5这五个数,其含义如下:
- -1 每个节点的ziplist字节大小不能超过4kb
- -2 每个节点的ziplist字节大小不能超过8kb
- -3 每个节点的ziplist字节大小不能超过16kb
- -4 每个节点的ziplist字节大小不能超过32kb
- -5 每个节点的ziplist字节大小不能超过64kb
# Lists may also be compressed.
# Compress depth is the number of quicklist ziplist nodes from *each* side of
# the list to *exclude* from compression. The head and tail of the list
# are always uncompressed for fast push/pop operations. Settings are:
# 0: disable all list compression
# 1: depth 1 means "don't start compressing until after 1 node into the list,
# going from either the head or tail"
# So: [head]->node->node->...->node->[tail]
# [head], [tail] will always be uncompressed; inner nodes will compress.
# 2: [head]->[next]->node->node->...->node->[prev]->[tail]
# 2 here means: don't compress head or head->next or tail->prev or tail,
# but compress all nodes between them.
# 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail]
# etc.
list-compress-depth 0
头和尾前几个不用压缩
push操作:
quicklist最重要的操作就是首尾插入节点,此操作由quicklistPush函数实现。PUSH操作不管是头部还是尾部压入都包含两个步骤:
- 如果插入节点中的ziplist大小没有超过限制(list-max-ziplist-size),那么直接调用ziplistPush函数压入
- 如果插入节点中的ziplist大小超过了限制,则新建一个quicklist节点(自然会创建一个新的ziplist),新的数据项会压入到新的ziplist,新的quicklist节点插入到原有的quicklist上
/* Wrapper to allow argument-based switching between HEAD/TAIL pop */
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) { //插入到quicklist的前面
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) { //插入到quicklist的尾部
quicklistPushTail(quicklist, value, sz);
}
}
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
assert(sz < UINT32_MAX); /* TODO: add support for quicklist nodes that are sds encoded (not zipped) */
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) { //如果还允许插入
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD); // 就插入头部的ziplist
quicklistNodeUpdateSz(quicklist->head);
} else {
quicklistNode *node = quicklistCreateNode(); // 创建一个quicklist的node
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD); //node中的ziplist插入新值
quicklistNodeUpdateSz(node); //node更新长度
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++; //quciklist的entry总和增加
quicklist->head->count++; //ziplist的长度增加
return (orig_head != quicklist->head);
}
likely:阅读和理解代码的角度来看,是一样的.目的是将“分支转移”的信息提供给编译器,这样编译器可以对代码进行优化, 以减少指令跳转带来的性能下降。
https://blog.csdn.net/edonlii/article/details/8877239
_quicklistNodeAllowInsert
#define sizeMeetsSafetyLimit(sz) ((sz) <= SIZE_SAFETY_LIMIT)
/* Maximum size in bytes of any multi-element ziplist.
* Larger values will live in their own isolated ziplists. */
#define SIZE_SAFETY_LIMIT 8192
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) { //fill负数是ziplist的entry大小的限定,正数是entry个数的限定
if (unlikely(!node))
return 0;
int ziplist_overhead;
/* size of previous offset */
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead;
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill))) //如果fill是负数并且符合要求
return 1;
/* when we return 1 above we know that the limit is a size limit (which is
* safe, see comments next to optimization_level and SIZE_SAFETY_LIMIT) */
else if (!sizeMeetsSafetyLimit(new_sz)) //新的entry默认还是有上限的
return 0;
else if ((int)node->count < fill) //fill是证书,代表ziplist中的最大entry个数
return 1;
else
return 0;
}
static const size_t optimization_level[] = {4096, 8192, 16384, 32768, 65536};
REDIS_STATIC int
_quicklistNodeSizeMeetsOptimizationRequirement(const size_t sz,
const int fill) {
if (fill >= 0) //如果是对entry个数的限定。先返回0,不判断
return 0;
size_t offset = (-fill) - 1; //对entry大小的判断
if (offset < (sizeof(optimization_level) / sizeof(*optimization_level))) { //判断entry的大小
if (sz <= optimization_level[offset]) {
return 1;
} else {
return 0;
}
} else {
return 0;
}
}
quicklistNodeUpdateSz
#define quicklistNodeUpdateSz(node) \
do { \
(node)->sz = ziplistBlobLen((node)->zl); \
} while (0)
_quicklistInsertNodeBefore
/* Wrappers for node inserting around existing node. */
REDIS_STATIC void _quicklistInsertNodeBefore(quicklist *quicklist,
quicklistNode *old_node,
quicklistNode *new_node) {
__quicklistInsertNode(quicklist, old_node, new_node, 0);
}
/* Insert 'new_node' after 'old_node' if 'after' is 1.
* Insert 'new_node' before 'old_node' if 'after' is 0.
* Note: 'new_node' is *always* uncompressed, so if we assign it to
* head or tail, we do not need to uncompress it. */
REDIS_STATIC void __quicklistInsertNode(quicklist *quicklist,
quicklistNode *old_node,
quicklistNode *new_node, int after) {
if (after) {
new_node->prev = old_node;
if (old_node) {
new_node->next = old_node->next;
if (old_node->next)
old_node->next->prev = new_node;
old_node->next = new_node;
}
if (quicklist->tail == old_node)
quicklist->tail = new_node;
} else {
new_node->next = old_node;
if (old_node) {
new_node->prev = old_node->prev;
if (old_node->prev)
old_node->prev->next = new_node;
old_node->prev = new_node;
}
if (quicklist->head == old_node)
quicklist->head = new_node;
}
/* If this insert creates the only element so far, initialize head/tail. */
if (quicklist->len == 0) {
quicklist->head = quicklist->tail = new_node;
}
if (old_node)
quicklistCompress(quicklist, old_node);
quicklist->len++;
}
quicklistPushTail(quicklist, value, sz);
/* Add new entry to tail node of quicklist.
*
* Returns 0 if used existing tail.
* Returns 1 if new tail created. */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(quicklist->tail);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}
和插入头差不太多的操作