
跳跃表简介:
跳跃表是一个有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。和链表、字典等数据结构被广泛地应用在Redis内部不同,Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构。
数据结构:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; //保存的元素
double score; //分值
struct zskiplistNode *backward; //后退指针
struct zskiplistLevel {
struct zskiplistNode *forward; //前进指针
unsigned long span; //跨度
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length; // 记录跳跃表长度,也是跳跃表目前包含节点的数量(表头节点不计算在内)
int level; //记录目前跳跃表内,层数最大的那个节点的层数
} zskiplist;
内存示意图:
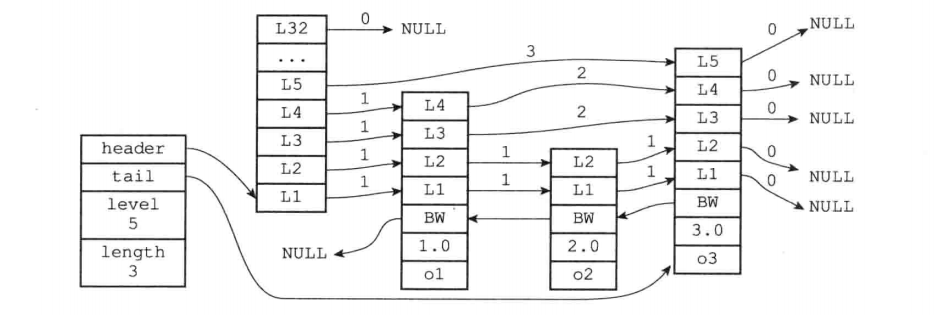
跳跃表的API:
创建:
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
插入:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score)); //检查是否是数字
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; //如果i是最高一层就是0,否则先继承i+1的值
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0))) //如果插入的节点更大
{
rank[i] += x->level[i].span; //rank加这个节点的span值
x = x->level[i].forward; //跳到这层的下一个节点
}
update[i] = x; //跳出while的循环表示节点要插入这个层目前节点(x)的后方
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel(); //为这个节点创一个高度
if (level > zsl->level) { //如果这个节点高度是最高的
for (i = zsl->level; i < level; i++) { //原来高度之上的做处理
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length; //跨度设置为原来zsl的长度
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) { //开始处理0-level区间
x->level[i].forward = update[i]->level[i].forward; //Xnode的处理
update[i]->level[i].forward = x; //原来zskiplist上的node处理
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1; //前面的节点对应level的调整
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward) //如果不是最后一个
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
查询:
/* Finds an element by its rank. The rank argument needs to be 1-based. */
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) { //从level有值的开始找,比较快
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span;
x = x->level[i].forward;
}
if (traversed == rank) {
return x;
}
}
return NULL;
}
删除
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x; //对zsl进行修改都要记一下update
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
/* Internal function used by zslDelete, zslDeleteRangeByScore and
* zslDeleteRangeByRank. */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
总结:
跳跃表也是一个用空间换时间的一个好结构,主要弄懂insert的流程就可以掌握了。我觉得node的随机生成高度很妙,虽然生成zsl肯定不是最优的,但少去了后期节点变化所需要的维护。